مقدمة
في هذا المقال المكون من جزئين سوف نلقي نظرة عامة على مجال معالجة النصوص باستخدام خوارزميات تعلم الآلة وسوف نلقى الضوء على تطور المجال بداية من استخدام الطرق التقليدية في معالجة النصوص مثل استخدام اسلوب (bag of words) التي تعتمد على عدد الكلمات إلى استخدام الطرق الحديثة مثل (word embedding) و كذلك استخدام تقنيات التعلم العميق (deep learning) في تحسين اداء الانظمة الحديثة التي نستخدمها حاليا في معظم المنتجات مثل انظمة الترجمة الآلية، تصحيح النصوص و البحث و غيره من التطبيقات.
قبل ان تكمل
في هذا المقال سوف نستعرض بعض الأمثلة باستخدام لغة البايثون (Python) لذا انصحك عزيزي ان لم يكن لديك خلفية عنها ان تطلع على كورس بسيط فيها و تعود لتكمل المقال، لن نقوم بالتطرق لمواضيع متقدمة للغاية في اللغة هنا لذا لابأس ان لم تقم باستخدام اللغة منذ فترة، نحتاج فقط الاساسيات هنا.
تطبيقات معالجة اللغة في حياتنا اليومية
يمكنك ان ترى تطبيقات معالجة اللغة بداية من هاتفك المحمول حيث يمكن للوحة المفاتيح ان تقترح عليك الكلمة القادمة بناءا على اسلوبك في الكتابة و كذلك بناءا على طبيعة اللغة و يتم هذا باستخدام عدة اساليب اشهرها استخدام نموذج للغة (language model)، ايضا يمكنك ان ترى جودة محركات البحث الحالية في فهم ما تريده عن طريق النص الذي تقوم بتزويد المحرك به فيمكن للمحرك ان يفهم المعنى الكامن في النص الذي قمت بإدخاله واستدعاء نتائج بحث تماثل المعنى الذي قمت بطلبه و من الآليات التي توفر لك مثل هكذا قدرات استخدام ال (word embedding) و سوف نتعرض لها في مقالنا هنا.
ليس فقط على مستوى الافراد يمكننا ان نرى هذه التطبيقات ولكن ايضا على مستوى الشركات، فعلى سبيل المثال بعض الشركات تقوم بعمل تحليل للنصوص على وسائل التواصل لتوفير معلومات عن السوق وعن ما يقوله عملائك عنك على وسائل التواصل، ويوجد شركات قامت بقطع شوط كبير في هذا المجال في وطننا العربي مثل شركة crowdanalyzer.
ايضا تقوم بعض الشركات بتطبيق معالجة اللغة في بناءا (chat-bots) تقوم بالتواصل معك من خلال خدمة الدردشة (chat) بدلا من التحدث مع احد ممثلي خدمة العملاء، بل ان شركة جوجل قامت بعرض خدمة جديدة تستبدل ممثل خدمة العملاء كليا اذ انك تتحث مع ال (bot) بالصوت وليس فقط من خلال النص كما هو الحال مع ال (chat-bots) التقليدية.
هذه فقط بعض الأمثلة البسيطة ولكن هناك العديد من التطبيقات في حياتنا يمكنك الإطلاع على بعضها من خلال هذا الرابط
بعض اشهر التطبيقات
في البداية دعنا نستعرض بعض التطبيقات التي نقوم باستخدام معالجة النصوص بها.
تحديد نوع النص (text classification)
اشهر التطبيقات هي تحديد نوع النص من بين انواع محددة (text classification) مثل ان نقوم بتحديد ما إذا كان النص بصيغة المدح ام الذم، على سبيل المثال عند عرض مراجعات منتج معين نريد معرفة ما اذا كانت المراجعة ايجابية ام سلبية و هذا التطبيق تحديدا يسمى (sentiment analysis) و هو تحليل للمشاعر، يمكن ايضا ان تتسع الاختيارات فتشمل انواع اخرى مختلفة مثل ان نقوم بتحديد ما اذا كان الخطاب به عنف ام لا او ان نقوم بتحديد الفئة التي ينتمي اليها النص من بين مجموعة فئات كأن يكون ترفيهي او علمي او رياضي على سبيل المثال.
فكما ترى استخدامات تحديد النص كثيرة للغاية و منتشرة بشكل كبير جدا و غالبا ما تجد المصادر التعليمية تهتم بها في بداية تعلمك لمجال معالجة اللغة لاهميتها وكذلك سهولة فهمها وتطبيقها.

الترجمة الآلية (Neural Machine Translation - NMT)
احد اشهر التطبيقات التي نستخدمها هي الترجمة الآلية (Neural Machine Translation - NMT) و هي تشرح نفسها إلى حدا كبير، هي ان تقوم الآلة من تلقاء نفسها بترجمة النص بشكل اوتوماتيكي، كما ترى في خدمة ترجمة جوجل على سبيل المثال.

استخراج اجابة السؤال (Question Answering)
من اشهر التطبيقات ايضا تطبيق الإجابة على الاسئلة واستخراج الإجابة من النص (Question Answering) وفي هنا يكون هدف البرنامج هو استخراج إجابة سؤال معطى من المستخدم من خلال قطعة نصية كما يقوم محرك البحث بإستخراج الإجابة عن سؤالك الذي قمت بكتابته في محرك البحث !
استخراج اسماء الكيانات (Named Entity Recognition - NER)
ايضا من التطبيقات التي يجب ذكرها هو استخراج اسماء الكيانات (Named Entity Recognition - NER) و هنا نقوم باستخراج من النص الاسماء التي تدل على مؤسسات مثلا، عملات او حتى اسماء لاشخاص.

هذه فقط بعض التطبيقات و يوجد تطبيقات اخرى مهمة مثل تلخيص النصوص (text summarization) و استخراج الكلمات التي تشير لنفس الكيان (Coreference Resolution) وايضا تحويل النصوص إلى صوت (text to speech - TTS) و العديد من التطبيقات الأخرى، يمكنك الإطلاع عليهم وعلى احدث ما توصل إليه العلم في هذه المجالات من خلال هذا الرابط.
كيف تعمل هذه التطبيقات
معالجة النصوص تتم بأكثر من طريقة في الحقيقة، بعض الطرق يكون بسيط للغاية ولكنه ذكي إلى حد كبير إذ يعتمد بشكل اساسي على قواعد مسبقة لدى البرنامج ويقوم بتنفيذها، تطبيق بسيط للغاية لهكذا تطبيق يمكن ان يكون في الشات بوت مثلا لرد التحية.
import random
replies = [ 'hi my name is bot !',
'morning how can i help ?',
'What can i help you with sir ?']
user_input = input("please enter a message")
if user_input in ['hello', 'welcome', 'hi', 'aloha']:
print(random.choice(replies))
هنا يمكنك ان ترى بوضوح ان في حالة ادخال المستخدم نص مختلف عن الذي كنت تتوقعه فلن يفهم البرنامج ما قام المستخدم بقوله، ولهذا تعتمد طريقة ال (Rule Based) على ان يقوم كاتبها بتغطية تقريبا كل الحالات التي يمكن ان يقولها المستخدم، وقد اعتادت هذه الطريقة ان تستخد في السابق و لازالت تستخدم حتى الآن منفردة في بعض التطبيقات المحدودة و ايضا تستخدم بجانب استخدام تعلم الآلة لتغطية بعض الحالات التي لدينا معرفة مسبقة عنها.
و يمكننا معالجة النص باستخدام طريقة التعلم من خلال البيانات، وهذه الطريقة هي الاكثر استخداما حاليا وتشهد تطور كبير بالتبعية لتطور تطبيقات تعلم الآلة (machine learning) و تطبيقات التعلم العميق (deep learning)، وهذه الطريقة هي التي سنقوم بتغطيتها بشئ من التفاصيل في هذا المقال.
ما سبق من التطبيقات تعتمد على تمثيل النصوص بشكل ما يسمح بمعالجتها بشكل سريع و ذو كفاءة عالية، و تختلف طريقة تمثيل النصوص من تطبيق لآخر لذا في هذا الجزء من المقال سوف نقوم بالتركيز على تمثيل النص بالنسبة لتطبيق تحديد النص (text classification) لسهولته كما ذكرنا من قبل.
ربما تتذكر من مقالنا السابق عن تعلم الآلة كيفية عمل النزول التدريجي (gradient descent) وكيف انه يقوم بتحديد اوزان لمجموعة متغيرات ثم نقوم بتقدير هذه الاوزان عن طريق حساب مدى الخطأ، يمكنك الرجوع إلى المقال لاسترجاع هذه المعلومة.
اذا يجب ان نقوم بإستخراج خصائص لهذا النص تقوم بتوصيفه وتمييزه عن باقي النصوص، ابسط انواع الخصائص التي يمكننا استخراجها من النص هي الكلمات، فدعنا نرى كيف نستخرج الكلمات كخصائص للنص.
تمثيل النص من خلال عدد الكلمات (bag of words - bow)
استخراج مكونات النص (Tokenization)
يجب التركيز على نقطة مهمة قبل البدأ في استخراج الخصائص من النص و هي تعريف الكلمة، اذ ان تعريف الكلمة مؤخرا اختلف من طريقة لأخرى، لنكون دقيقين اكثر ما هو تعريف الوحدة النصية (token) في النص الذي نعمل عليه، اذا كانت كلمة فيمكن ان تكون كلمة (يحبه) و (احبه) و (تحبه) كلمات مختلفة تمام عن بعضهم البعض، بينما بعض الطرق تقوم بتفكيك الكلمة و جعلها (ي + حب + ه) و (ا + حب + ه) يمكنك ان ترى ما يحدث هنا، نحن نقوم بتفصيل النص و استخراج مكوناته، هذه العملية مهمة اذ انها الاساس لما هو قادم لان كل وحدة (token) ستعتبر خاصية من خصائص النص، اذا فمثالنا السابق عن الحب بدلا من تصبح (يحبه) صفة من صفات النص ستصبح (ي) و (حب) و (ه) من خصائص النص و هكذا عند استخدام اشكال مختلفة من الفعل ستدري ان الأصل حب.
لاحظ ان هذه الطريقة لا تقوم باستخراج اساس الكلمة و هي لاتدري ان حب بالضرورة كلمة صحيحة هي تعمل على اساس معين و خطوات معينة يمكنك الإطلاع عليه من خلال هذا الرابط.
بناء قاعدة الكلمات (vocabulary)
سوف نعتمد في البداية على طريقة التقسيم على اساس المسافات اي ان الوحدة النصية ستصبح الكلمة التي تأتي بعدها مسافة، لنستطيع تمثيل النصوص باستخدام هذه الخصائص يجب علينا في البداية ان نقوم بتحديد الصفات التي سوف نقوم بتوصيف النص على اساسها، في هذه الحالة الصفات هي الكلمات اذا لنقم بتحديد كل الكلمات التي يمكننا ان نصف النص بناءا عليها و سوف نسميها قاعدة الكلمات (Vocabulary) او القاموس الخاص بالنموذج الخاص بنا.
دعنا نرى مثال باستخدام مكتبة sklearn في لغة البايثون.
from sklearn.feature_extraction.text import CountVectorizer
text =[
"مرحبا",
"اهلا يا صديقي",
"كيف حالك يا صديقي",
"مرحبا صديقي"
]
vectorizer = CountVectorizer()
vectorizer.fit(text)
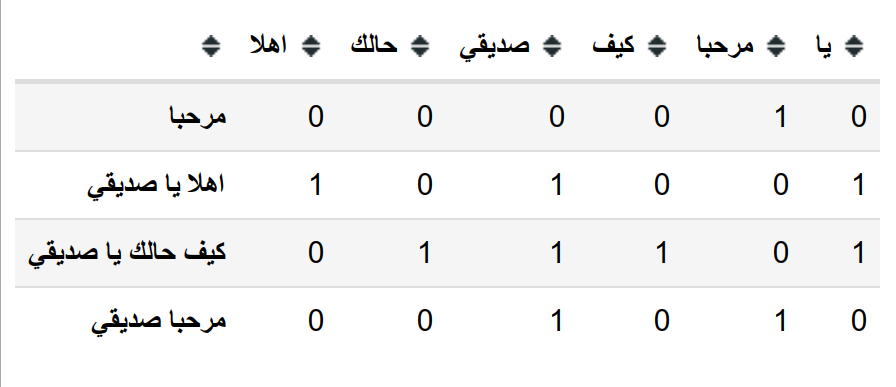
كما ترى هنا قاعدة الكلمات الخاصة بنا هي الكلمات المميزة في جميع النصوص و يتم توصيف النص من خلال عدد الكلمات التي تظهر به، فعلى سبيل المثال يمكن ان نرى هنا ان النص "مرحبا يا صديقي" يتم تمثيله بالارقام
[0, 0, 1, 0, 1, 1]
تعد هذه الطريقة الابسط في تمثيل النصوص و يمكن استخدامها كممثل للنص كما نرى و في المثال القادم نقوم بعمل نموذج بسيط باستخدام sklearn مرة اخرى يقوم بتحديد المشاعر في النص (sentiment analysis) على بعض التغريدات من موقع تويتر
تتوفر البيانات على شكل ملفيين احدهم يحتوى على التغريدات الإيجابية و الاخر على السلبية لذا سنقوم بتجميعهم و استخراج الخصائص منهم.
# read the data
pos_reviews = pd.read_csv("train_Arabic_tweets_positive_20190413.tsv", sep='\t', header=None)
neg_reviews = pd.read_csv("train_Arabic_tweets_negative_20190413.tsv", sep='\t', header=None)
dataset = pd.concat([pos_reviews, neg_reviews])
dataset.columns = ['sentiment', 'text']
dataset.head()
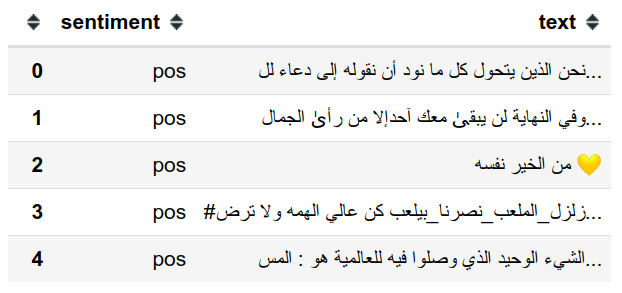
dataset['sentiment'].value_counts()
>>> pos 22761
>>> neg 22514
>>> Name: sentiment, dtype: int64
هنا نرى ان البيانات متوازنة بشكل كبير اذ ان عدد التغريدات الإيجابية قريب جدا من السلبية، والان سوف نقوم بتقسيم البيانات إلى جزء للتعلم و جزء للاختبار (train test split)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(dataset['text'], dataset['sentiment'], test_size=.2)
x_train.shape, x_test.shape
>>> ((36220,), (9055,))
والان يمكننا ان نقوم بتكوين قاعدة الكلمات و نرى جزء منها.
vectorizer = CountVectorizer(max_features=1500)
vectorizer.fit(x_train)
هنا قمنا بتحديد عدد اقصى للخصائص التي يمكن تجميعها للحفاظ على الذاكرة و كذلك لتبسيط المثال ولكن في المتوسط تطبيقات اللغة تحتوى على كلمات اكثر بكثير.
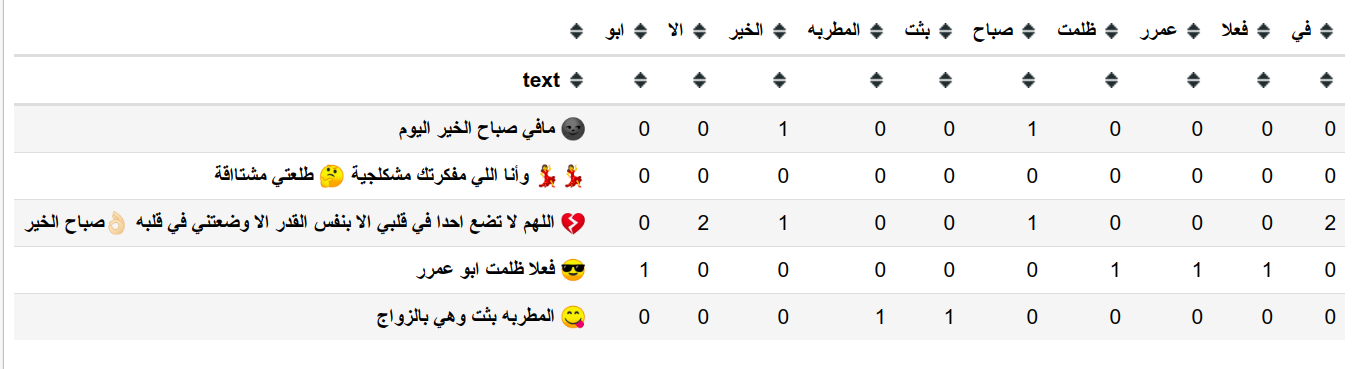
يجب ان نقوم بتحويل النص إلى ارقام كما قمنا من قبل لنستطيع استخدام نموذج تعلم آلة (machine learning) على البيانات.
x_train_v = vectorizer.transform(x_train)
x_test_v = vectorizer.transform(x_test)
الآن يمكننا ان نقوم بتدريب نموذج بسيط مثل (Logistic Regression) و هو نموذج يستخدم في التحديد والاختيار (Classification).
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(x_train_v, y_train)
والان يمكننا قياس جودة النموذج عن طريق مدى دقته على البيانات التي لم يراها من قبل
(لاحظ ان هناك طرق اخرى لقياس مدى جودة النموذج مثل ال recall او التغطية و كذلك قياس ال f1-score وهي طريقة تجمع بين ال precision (الدقة في حالة الإختيار/ classification) و ال recall/التغطية )
clf.score(x_test_v, y_test)
>>> 0.7168415240198786
عيوب هذه الطريقة
يمكنك ان ترى ان قاعدة الكلمات تحتوي على كلمات كثيرة مثل (في، إلا، على، وهكذا) و هذه الكلمات تسمى كلمات وقف (stopwords) فهي لاتضيف كثيرا للمعنى وانما تستخدم لترتيب و تشكيل اللجملة فهذه الكلمات تأخذ مساحة كبيرة من الكلمات ولكنها ليست ذات اهمية كبيرة.
ايضا يمكننا ان نرى ان عدد الكلمات يمكن ان يزيد بشكل كبير جدا لان الوحدة الاساسية (token) بالاساس تستخرج على اساس المسافة و كما وضحنا سابقا فان هناك طرق افضل في استخراج الكلمات (tokenization) هذه الطرق تساهم بشكل كبير في تقليل المساحة المستخدمة.
ايضا من المشاكل التي يمكنك ملاحظتها هي ان الترتيب لا يعتد به على الإطلاق، اذ ان الجملتين الاتيتين لهما تقريبا نفس التمثيل.
reviews = [ "انا احب هذا المنتج كثيرا لا يوجد لدي اي شكوى",
"انا لا احب هذا المنتج على الإطلاق لدى مليون شكوى"]

فعلى الرغم من اختلافهم كليا الا ان هذه الطريقة لا تعتد بالترتيب لانه لايوجد ما يخبر البرنامج ان كلمة (احب) قد سبقها (لا)، لذا يجب ان نوجد حل لهذه المشكلة ايضا.
من عيوب هذه الطريقة ايضا انها لا تعطي اي مؤشر للكلمات المتشابهة، بمعنى ان كلمة (عشق) و كلمة (حب) لا يوجد اي دلالة على تشابهما بينما ان امكنا تحصيل معلومة كهذه فقد تفيدنا جدا.
ايضا ماذا إن ادخل المستخدم كلمة جديدة لم يراها النموذج اثناء التدريب، حينها سيتجاهلها النموذج بالكلية لانها لا تعتبر من الخصائص/القاموس الخاص بالنموذج.
يمكنك ان ترى ان هناك العديد من المشاكل ولكن لاتقلق هناك حلول لهذه المشاكل كما سنرى فيما يلي.
تمثيل النص من خلال معدلات التكرار و الندرة (TF-IDF)
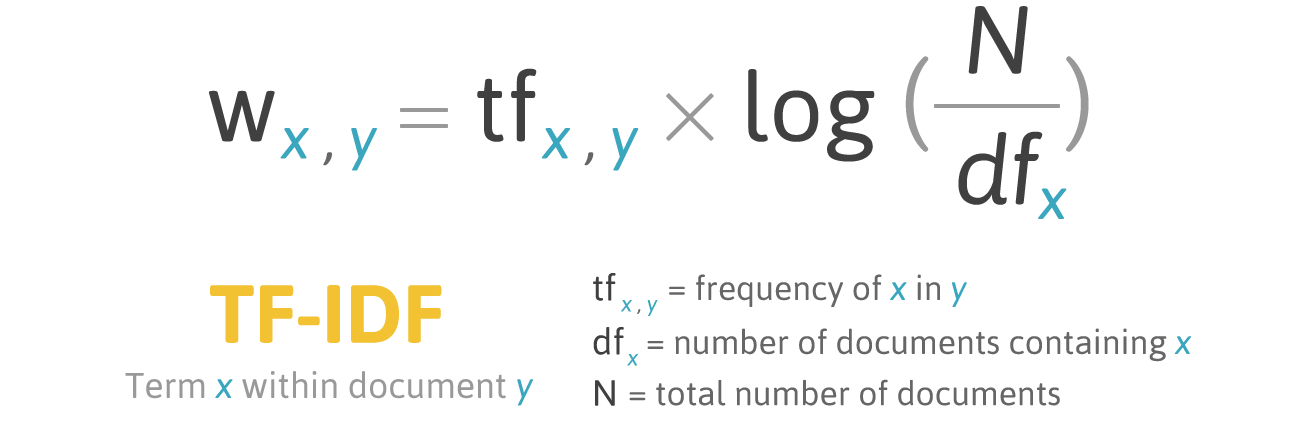
هناك طريقة اخرى و هي تعديل بسيط على الطريقة السابقة لحل مشكلة الكلمات التي ليس لها اهمية كبيرة وهي عن طريق حساب معدل تكرارها في النص المستخدم و كذلك كل النصوص المتاحة، اذ ان الكلمة المستخدمة بكثرة في جميع النصوص فهي ليست مهمة بالضرورة مثل الكلمات الاقل ظهورا.
تقوم الطريقة بالاساس بتعيين قيمة لكل كلمة تعبر عن اهميتها و كلما زادت اهمية الكلمة كلما زادت القيمة.
\[W_x = tf_x \times \log(\frac{N}{df_x})\]
تقوم المعادلة بالأساس عن طريق حساب معدل تكرار الكلمة في النص الحالي (term frequency - tf) و كذلك حساب عدد النصوص التي ظهرت بها هذه الكلمة (document frequency - df) دعنا نستعرض مثال لكلمة مستخدمة كثيرا مثل حرف الجر (في) سوف نجد انها تقريبا سوف تظهر في كل النصوص وبهذا سوف تكون قيمة ال (df) كبيرة و قريبة جدا من (N) و هو عدد النصوص المتاحة اذا ستكون محصلة العملية log(N/df) قريبة من 0 لان كلما زادت قيمة df كلما نقصت قيمة الكسر و بالتبعية قيمة اللوغاريتم على عكس لو نقصت قيمة ال df كلما زادت قيمة الكسر و كذلك تزداد قيمة اللوغاريتم، الذي يرمز له غالبا بالقيمة (inverse document frequency - idf).
هنا يمكن ان نرى مثال على استخدام tfidf على جزء من البيانات
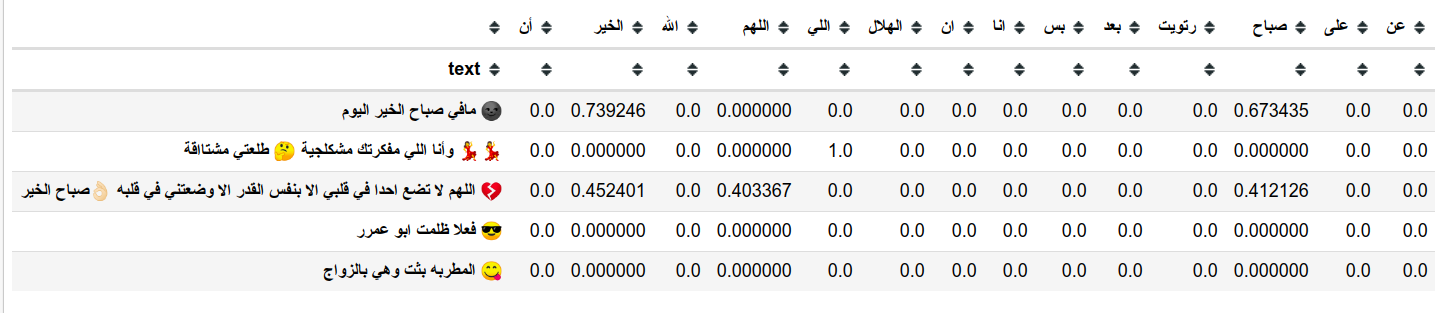
كما ترى فإن لكل كلمة قيمة ناتجة من حساب معدل التكرار وليس مجرد عددها كما كان في السابق.
يمكننا تغير سطر واحد فقط في البرنامج السابق لاستخدام معدل التكرار (tf-idf) بدلا من العدد فقط (count vectorizer).
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
vectorizer.fit(x_train)
سوف نلاحظ زيادة طفيفة في جودة توقعاتنا ولكن سوف تظل مشاكل اخرى قائمة مثل ان (لا احب) يتم قراءتها على انها (لا) و (احب) و في هذا الإطار نرى ان كلمة احب بالتأكيد تدل على رأي إيجابي لذلك غالبا سوف يتوقع نموذجنا ان النص ايجابي، وسوف نقوم باستعراض طريقة يمكنها حل هذه المشكلة بنسبة جيدة.
تمثيل النص باستخدام مجموعة كلمات (N-gram)
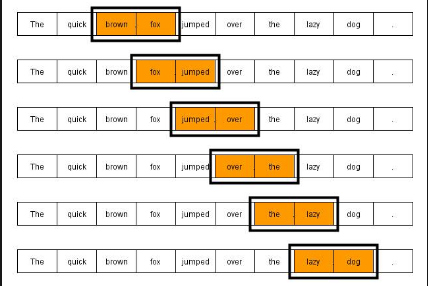
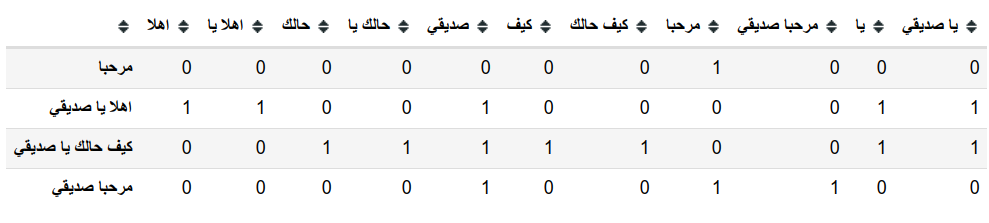
لمعالجة مشكلة مثل (لا احب) وايضا الكلمات المركبة بشكل عام مثل (أبو بكر) وايضا (حسبي الله ونعم الوكيل) على سبيل المثال نحتاج لان ننظر ليس فقط لكلمة واحدة وانما ننظر إلى عدة كلمات متتالية مرة واحدة، وهذه هي طريقة ال (ngrams) التي تعتمد على وجود نافذة بحجم معين (مثلا كلمتين) ونختار كل كلمتين متتاليتين ليصبحوا وحدة نصية (token)، اذا كانت النافذة ذات حجم 3 يصبح مسماهم (trigrams) و هكذا.
text =[
"مرحبا",
"اهلا يا صديقي",
"كيف حالك يا صديقي",
"مرحبا صديقي"
]
# bigram example
vectorizer = CountVectorizer(ngram_range=(1, 2))
vectorizer.fit(text)
text =[
"مرحبا",
"اهلا يا صديقي",
"كيف حالك يا صديقي",
"مرحبا صديقي"
]
# trigram example
vectorizer = CountVectorizer(ngram_range=(1, 3))
vectorizer.fit(text)

استخدام مجموعات الكلمات (ngram) سوف يحسن اداء النموذج الخاص بك لانه يوفر للنموذج نافذة اكبر يستطيع النظر من خلالها للنص ولكنه يزيد من عدد الخصائص بشكل كبير كما ترى و ايضا مازالت هناك بعض المشاكل التي لم نقم بحلها بعد مثل الترتيب وكذلك مدى تشابه الكلمات ذات المعاني المتقاربة.
تمثيل النص باستخدام متجهات المعاني (word embeddings)
حتى الآن كان تمثيلنا للنص مقتصر على شكل مجموعة ارقام تمثل النص ككل، ولكن الآن نريد عمل تمثيل للكلمة الواحدة في شكل متجه (vector) والذي سوف يكون مفيد في استخدامات كثيرة خاصة في مجالات التعلم العميق (deep learning) فدعنا نرى بعض اشهر الطرق في تمثيل النص على شكل متجه.
الترميز التقليدي للكلمة الواحدة (one hot encoding)
في هذه الطريقة سوف نقوم بتحديد رقم لكل كلمة من الكلمات المميزة التي لدينا ثم نقوم بتمثيل كل كلمة على شكل متجه طوله عدد الكلمات المميزة لدينا و قيمته صفر في جميع الاماكن ماعدا إحداثي الكلمة، يمكنك ان ترى بشكل اوضح في المثال الآتي.
from collections import defaultdict
text = "مرحبا هلا يا صديقي كيف حالك يا صديقي مرحبا صديقي"
text2idx = defaultdict(lambda: 0)
for i, word in enumerate(set(text.split()), 1):
text2idx[word] = i
text2idx['مرحبا']
>>> 5
هنا قمنا ببناء المتغير
text2idx حيث يحتوي على كل كلمة والرقم المقابل لها و استخدمنا هنا defaultdict حتى نحصل على قيمة 0 عندما نستخدمه مع كلمات جديدة، الآن دعنا نستخدم ما قمنا بعمله لتكوين المتجه المعبر عن الكلمة.
import numpy as np
word = 'مرحبا'
word_vector = np.zeros((len(text2idx.keys())))
word_vector[text2idx[word]] = 1
word_vector
>>> array([0., 0., 0., 0., 0., 1., 0.])
كما ترى هنا قمنا بعمل متجه فارغ بحجم مجموع الكلمات التي لدينا و من ثم قمنا بتغير قيمة احداثي هذه الكلمة فقط ليصبح قيمته 1 و اذا استخدمناه مع كلمة جديدة سوف نحصل على تمثيل مثل ما يلي.
word = 'مصر'
word_vector = np.zeros((len(text2idx.keys())))
word_vector[text2idx[word]] = 1
word_vector
>>> array([1., 0., 0., 0., 0., 0., 0.])
الكلمات التي لم نراها من قبل والتي لم تكن متواجدة في البيانات التي تمرنا عليها سوف تحصل على متجه يحتوي على 1 في الخانة الاولى التي خصصناها للكلمات الخارجة عن القاموس الخاص بنا (Out of Vocab).
تمثيل النصوص بهذه الطريقة مهم للغاية حيث انه يتم استخدامه في الطرق الحديثة كما سنرى لاحقا. ولكن كما ترى فهو لا يحتوي على اي معلومة عن الكلمة ماعدا رقم الكلمة في قاموس كلماتنا و هذه ليست معلومة يمكننا من خلالها استخراج معاني مفيدة عن التشابه بين الكلمات و معانيها.
متجهات الكلمات ذات المعنى (word2vec)
تخيل ان تقوم بعمل عملية حسابية على الكلمات كالمثال الآتي.
القاهرة - مصر + فرنسا ~= باريس
في هذه المعادلة نقوم باستخراج باريس بناءا على العلاقة بين مصر و القاهرة اذ ما تقوله المعادلة هو العلاقة بين القاهرة و مصر كالعلاقة بين فرنسا و ماذا ؟ بالطبع يمكنك ان تتخيل ان الإجابة باريس عاصمة فرنسا، ولكن كيف يمكننا تطبيق هذه المعادلة بالفعل اذ يقوم البرنامج بالإجابة عوضا عنا بباريس؟
في ورقتهم العلمية توماس ميكولوف وزملائه قامو بإقتراح نموذج صياغة للكلمات على شكل متجه بحيث يحتوي المتجه على معلومات عن الكلمة، والكلمات التي تظهر مع نفس المحيط من الكلمات سوف تحصل على متجهات متشابهة، لن نتطرق لتفاصيل عمل النموذج في الوقت الحالي لكن يمكنك الإطلاع عليه من خلال هذا المقال الرائع لكن دعنا نرى كيفية استخدام هذا النموذج و كيف يمكنه ان يفيدنا في عملية معالجة النصوص من خلال مكتبة spaCy.
$pip install spacy
$python -m spacy download en_core_web_md
الآن قمنا بتحميل المكتبة والملفات التي نحتاجها لتوليد متجهات الكلمات، لنرى كيف يمكننا استخدامها.
import spacy
nlp = spacy.load("en_core_web_md")
cat = nlp("cat")
cat.vector[:10]
>>> array([-0.15067 , -0.024468, -0.23368 , -0.23378 , -0.18382 , 0.32711 ,
>>> -0.22084 , -0.28777 , 0.12759 , 1.1656 ], dtype=float32)
حصلنا الآن على المتجه الخاص بكلمة قطة، المتجه يحتوي على 300 رقم ولكن استعرضنا فقط اول 10 منهم، الآن دعنا نحصل على متجهيين اخريين.
dog = nlp("dog")
car = nlp("car")
لاحظ الآن كيف يمكننا مقارنة الكلمات.
cat.similarity(car)
>>> 0.3190752856973872
cat.similarity(dog)
>>> 0.8016854705531046
كما ترى على الرغم من تشابه كلمة (cat) و (car) من حيث الأحرف، إلا ان التشابه بينهم ضعيف جدا مقارنة بالتشابه بين (cat) و (dog) هذا لان المعنى اقرب بالطبع، فكما ترى ان متجهات الكلمات تتضمن المعاني بداخلها و بالطبع المعاني المتضمنة داخل المتجهات تأتي بعد تدريب معين لن يسعنى تغطيته في الوقت الحالي لكن يمكنك الإطلاع على الورقة البحثية التي اشرنا إليها.
تتم حساب نسبة التشابه بين المتجهات على اساس جيب الزاوية (cosine) بينهم، يمكنك الإطلاع على طريقة حسابها من هنا
لاحظ ان مكتبة
spaCy تستخدم نموذج مختلف قليلا عن الذي اشرنا إليه في الورقة البحثية لكنه يقوم بنفس الوظيفة بشكل افضل قليلا، يمكنك الإطلاع عليه من خلال الورقة البحثية الخاصة به من هذا الرابط
استخدام المتجهات في تطبيق تحديد العاطفة في النص
لنقوم باستخدام المتجهات مع نماذجنا يجب علينا ان نعيد تمثيل النص على هيئة متجهات، ولكن نحن نحصل على متجه لكل كلمة فكيف نحصل على متجه للنص الكامل ؟
احد اشهر الطرق هي ان نقوم باستخدام مجموع المتجهات الخاصة بكل كلمة لتصبح المتجه الممثل للنص بكامله، هناك طرق اخرى سوف نتحدث عناه لاحقا ولكن الآن سوف نستخدم هذه الطريقة.
text = "this is a simple text"
vector = np.zeros((300,))
for word in nlp(text):
vector += word.vector
vector[:10]
>>> array([-0.46234499, 0.81979895, -0.83246968, 1.26062 , 0.389594 ,
>>> -0.428568 , 0.24449199, -1.57974999, 0.15832401, 9.83159995])
يمكنك ان تلاحظ هنا ان كل كلمة سوف يتم تمثيلها بمتجه يعبر عنها، ولان المتجهات الموجودة بالفعل في النموذج كثيرة وقد تكون اكثر من الكلمات التي تتدرب عليها في البرنامج الخاص بك، اذا قام المستخدم بإدخال كلمة جديدة لم يراها النموذج الخاص بك اثناء التدريب ولكن لها متجه معرف بالفعل فان النموذج الخاص بك سوف يحصل على متجه شبيه بالمتجهات التي حصل عليها اثناء تدريبه لان متجه هذه الكلمة لن يكون جديد كليا، دعنا نستعرض مثال على هذه الحالة تحديا.
دعنا نقول ان اثناء التدريب نوذجك تعرض لكلمة يحب ولكنه لم يتعرض لكلمة يعشق، وعند استخدام النوذج الخاص بك ادخل المستخدم كلمة يعشق، في الحالة العادية سوف يقوم النموذج بتجاهلها ولكن في هذه الحالة (لو كان لها متجه معرف في نموذج المتجهات الذي هو مختلف عن نموذجك الخاص) حين إذ سوف تحصل منها على متجه يشبه كثيرا المتجه الخاص بكلمة (يحب) وهكذا يمكن للنموذج الخاص بك ان يفهم انها ليست كلمة جديدة كليا وانما كملة شبيهة بكلمة تعرض لها مسبقا.
بعض الملاحظات على تمثيل النص بشكل متجهات الكلمات (word2vec/glove)
لاحظ هنا ان جودة تلك المتجهات تتوقف على جودة النموذج الذي استخدم في تكوينهم، اذ انه اذا كان ضعيفا ولم يتم توفير بيانات كافيه له فلن تحصل على متجهات فعالة وجيدة و انما متجهات غير معبرة لان في اغلب الاحيان لن يرى الكلمة اكثر من مرة في اكثر من موضع حتى يفهم المحتوى الذي تظهر به ليجد شبيهاتها من الكلمات.
لاحظ ايضا كيف ان المتجه الخاص بالكلمة لا يختلف بإختلاف مكان استخدامها، على سبيل المثال (صليت المغرب في المغرب) كما تلاحظ هنا ان (المغرب) الاولى تعني صلاة المغرب اما الثانية فتعني البلد، في حالة استخدامنا لنموذج مبنى بطريقة (word2vec) او طريقة (GloVe) -وهما الطريقتان المستخدمان في المتجهات التي قمنا بعرضها- سوف تحصل على نفس المتجه وهذا بالتأكيد ليس الحل الأمثل.
ايضا جمع المتجهات مكننا من تحصيل المعلومات الكامنة في النص بإكمله ولكن بالتأكيد لايغني عن حاجتنا لان نأخذ في اعتبارنا ترتيب النص، لان حتى بعد ان نقوم بجمع المتجهات، لن تختلف النتيجة بإختلاف ترتيب النص فمازلنا في حاجة إلى حل تلك المشكلة.
الاستنتاج
حتى الآن قمنا بتغطية العديد من الطرق لتمثيل النص وكيفية استخدامهم بلغة البايثون لعمل تطبيق بسيط للغاية، واستعرضنا اهم العقبات والمشاكل التي تواجه هذه الطرق و هكذا كيف ان هناك طرق اخرى لحل هذه المشاكل وهذا نهاية النصف الاول من هذه المقدمة المختصرة البسيطة عن معالجة الآلة باستخدام خوارزميات تعليم الآلة.
في الجزء القادم سوف نتحدث عن نماذج اخرى افضل في معالجة النصوص و كيفية معالجتها للمشاكل التي تعرضنا لها حتى الآن وايضا سنتحدث عن النماذج المستخدمة حاليا في التقنيات الحديثة التي نراها في تطبيقاتنا بشكل يومي.
في هذا المقال حاولت تبسيط بعض المصطلحات للغتنا العربية من اجل تسهيل عملية الشرح ولتبسيط المعلومة، في حالة اي خطأ املائي او اقتراح افضل للترجمة فأنا ارحب جدا بذلك يمكنك التعليق على المقال او مراسلتي لتعديل و تحسين المحتوى، ووفقنا الله وإياكم لما يحب ويرضى.




Comments