مقدمة
هذا المقال تكملة للمقال السابق، يمكنك الاطلاع عليه من هنا
في المقال السابق تحدثنا عن نماذج مختلفة لمعالجة النصوص باستخدام خوارزميات تعلم الآلة، وتوقفنا عند بعض النقاط عند كل نموذج، دعنا نراجعها سريعا.
- ذكرنا في المرة السابقة استخدام Bag of words و وضحنا ان هذا النموذج لايأخذ في الحسبان ترتيب الكلمات وايضا لا يستطيع فهم معاني الكلمات فبالنسبة لهذا النموذج كل الكلمات سواء و الفارق هو عدد مرات تكرارهم.
- ذكرنا ايضا كيف ان استخدام معدل تكرار الكلمة في النصوص (TFIDF) يمكن ان يساعد في تميز الكلمات المهمة عن باقي الكلمات ولكنه ايضا يعاني من نفس مشاكل الطريقة السابقة.
- ثم ذكرنا نموذج متجهات الكلمات word2vec و ذكرنا كيف ان استخدام هذا النموذج يساعد في الحصول على متجه يعبر عن معنى الكلمات ولكن مازال لدينا بعض الملحوظات مثل ان الكلمة تحصل على نفس المتجه بغض النظر عن اختلاف السياق.
في هذا المقال سنتعرف على كيفية التغلب على المشاكل السابقة باستخدام نماذج اكثر تطورا، سنتحدث عن الجمع بين نموذج word2vec و نموذج CNN لجمع اكتر من متجه و محاكاة طريقة ال N-Grams. أيضا سنتحدث عن محاكاة البيانات التسلسلية (sequential data) باستخدام نموذج RNN.
كيف يعمل word2vec
فهم كيفية عمل هذا النموذج سوف تساعدنا على معرفة حدوده بشكل افضل و ربما كيفية التغلب عليها!
يوجد نوعان من نموذج word2vec هما CBOW (continous bag of word) و skip-gram، النوعان يختلفان في طريقة تدريبهما قليلا لكن الاستخدام لاحقا يكون في نفس السياق الا وهو توليد متجهات ذات معنى للكلمة.
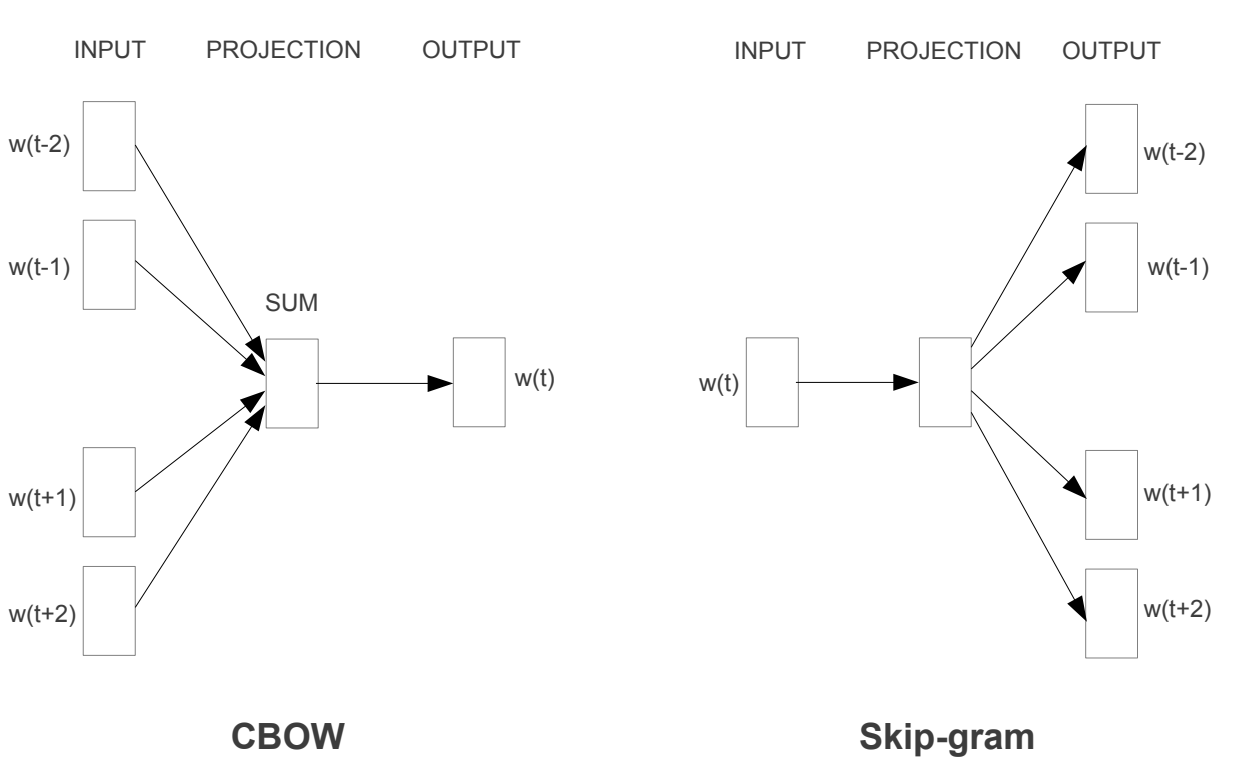
CBOW
طريقة ال CBOW تعتمد على تعلم الكلمة الوسطى من الكلمات المحيطة، هذا عن طريق ادخال متجهات الكلمات المحيطة و محاولة تعلم الكلمة الوسطى
بالطبع في البداية لن يتوقع النموذج الكلمة الصحيحة ولكن مع التدريب و محاولة تقليص الخطأ باستخدام اسلوب النزول التدريجي في معدل الخطأ (gradient descent) يتحسن اداء النموذج ليستطيع توقع الكلمة الصحيحة اذا ادخلنا الكلمات المحيطة، على سبيل المثال عندما ندخل للنموذج اريد ان ... كوب عصير، سيقوم النموذج بتوقع ان الكلمة الوسطى هنا هي "اشرب" لان هذا ما يدل عليه السياق.
نماذج التعلم العميق (deep learning) تعتبر بالاساس معادلات معقدة تحاول تخمين ما هي القيم التقريبية للمتغيرات التي تكون هذه المعادلات في البداية يتم تخمين قيم عشوائية لهذه المتغيرات و يتم احتساب قيم التوقعات و مقارنتها بالقيم الحقيقية و احتساب معدل الخطأ بينهما، و باستخدام خصائص التفاضل يمكننا معرفة التغييرات المطلوبة في كل متغير حتى نقوم بتقليل معدل الخطأ و يحدث هذا في عملية ال (gradient descent) يمكنك مراجعة تفاصيل اكثر في مقال سابق حيث نتحدث عن تفاصيل هذه العملية بشكل اكبر.
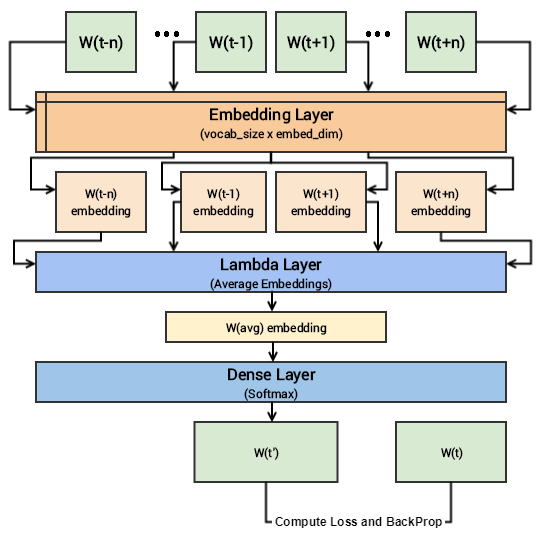
Skip-gram
طريقة ال skip-gram تعتمد على تعلم السياق من الكلمة الوسطى (عكس الطريقة السابقة).
لتبسيط طريقة تعلم هذا النموذج نقوم بتحضير المدخلات لهذا النموذج على النحو التالي.
| السياق |
الكلمة قبل |
الكلمة بعد |
صحة السياق |
| شرب |
اريد |
العصير |
1 |
| اكل |
اريد |
العصير |
0 |
يمكنك ان ترى هنا اننا استخدمنا كلمة واحدة قبل و بعد كلمة السياق لكن يمكن ان يكون اكثر او اقل (اقل بان نستخدم كلمة واحدة قبل او بعد).
هنا يصبح هدف النموذج ان يتوقع إذا كانت الكلمات المعطاه تنتمي الي نفس السياق ام لا و ايضا في البداية لن يتوقع النموذج الاجابة الصحيحة ولكن بعد التدريب و التصحيح يمكنه ذلك.
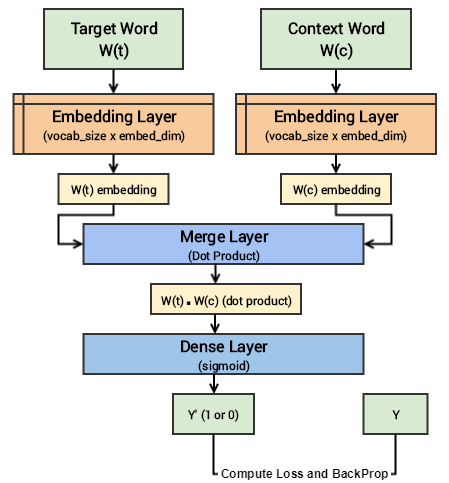
استخدام نماذج ايجابية و سلبية في التدريب يعد من اشهر الطرق في تدريب نماذج تعلم اللغة و تسمى هذه الطريقة بال (negative sampling) يمكنك الاطلاع على معلومات اكثر من خلال هذا الفيديو القصير.
الاستخدام بعد التدريب
بعد انتهاء عملية التدريب نقوم باستخراج مرحلة تحويل النص الي متجه (embedding layer) بعد ان تعلمت كيف تصف الكلمة المعطاه بمتجه يمثل معناها، و في هذه المرحلة كل كلمة تم التدريب عليها لها متجه ثابت الان لا يمكن تغييره بناءا على السياق الخاص بالجملة و لكنه بالتأكيد افضل من استخدام الطرق السابقة مثل (bag of words) للتعبير عن النصوص.
استخدام ال CNN في معالجة اللغة
تعد ال CNN (Convolutional Neural Network) الاكثر شهرة و استخداما في مجال معالجة الصور ولكن ايضا تستخدم في معالجة النصوص كما سنرى في الامثلة الاتية.
محاكاة مجموعة الكلمات من متجهات الكلمات (N-Gram using CNN)
تكلمنا في المقال السابق عن كيف ان استخدام اكثر من كلمة كوحدة للمعالجة (N-grams) يساعد على فهم معلومات اكثر في النص لان بعض المصطلحات يشمل اكثر من كلمة مثل مصطلح (حسبي الله و نعم الوكيل) على سبيل المثال.
يمكننا استخدام ال CNN لتحصيل المعلومات التي تشتمل عليها مجموعة كلمات من متجهاتها، باستخدام طبيعة ال CNN الالتفافية يمكننا ان نمر على اكثر من كلمة باستخدام نافذة متحركة بحجم معين (مثلا 3 للتعبير عن 3-grams) كما هو موضح في المثال بالاسفل.
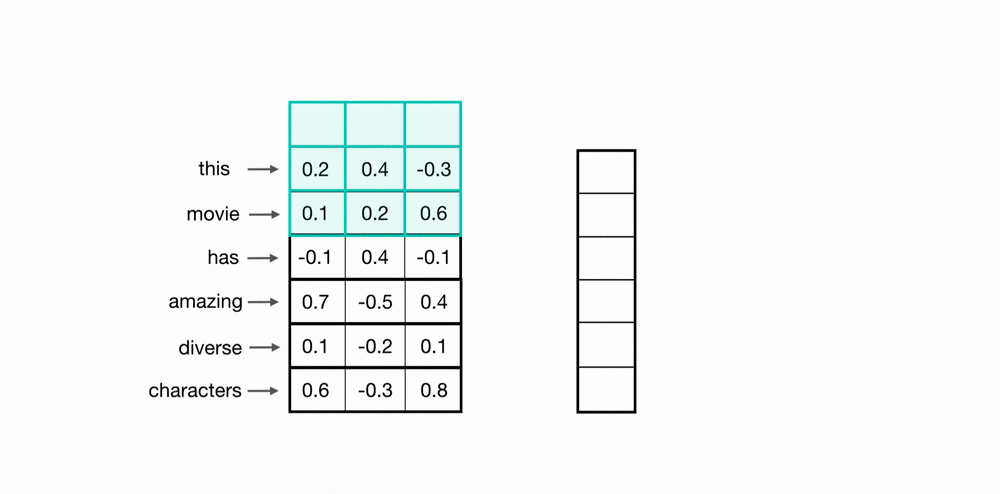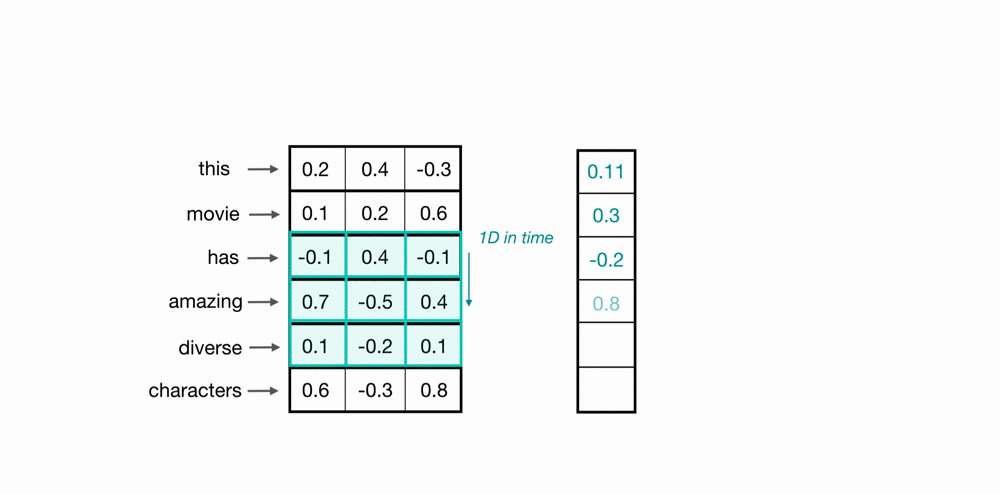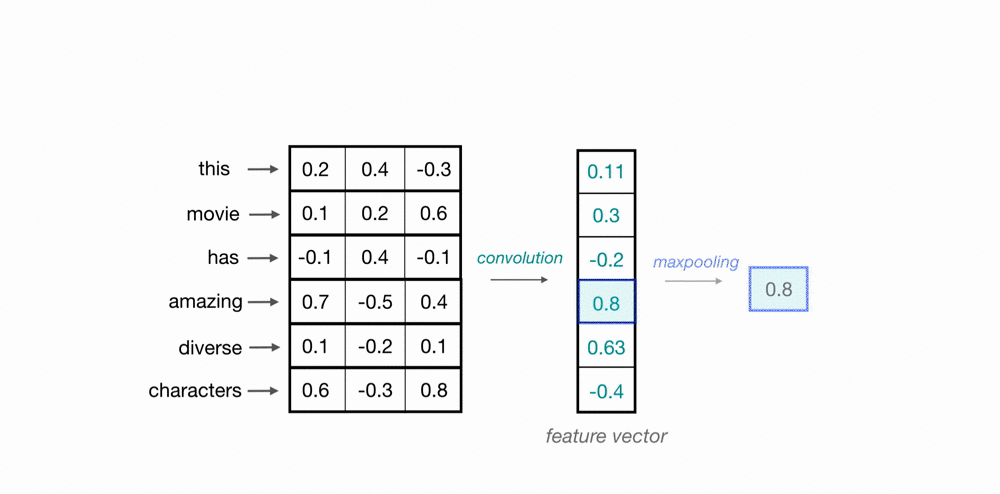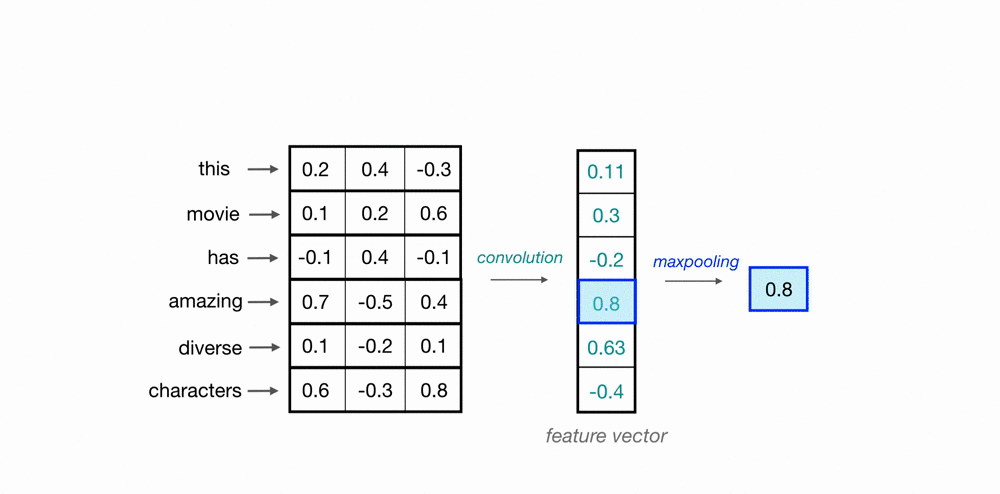
تعلم متجهات الاحرف (char embeddings)
يمكن ايضا استخدام ال CNN على مستوى الحروف لتعلم ما تعبر عنه الحروف و بالتالي ببناء اكثر من طبقة متتالية من نوعية CNN يمكن تكوين معرفة عن النص ككل، فكل طبقة/مرحلة سوف تتعلم مما تعلمته السابقة.
استخدام الحروف بدلا للكلمات يساعد على تفادي عدم معرفة الكلمات الجديدة، ويساعد ايضا على الاستفادة من التكوين المشترك لبعض الكلمات و الاجزاء المشتركة على سبيل المثال يمكننا ان ندرك ان يحب و احب و يحبوا يشتركوا في حرفي الحاء و الباء و لذلك فان الكلمات المشتقة منها يمكن للنوذج معرفتها على عكس النماذج التي تعتمد على الكلمات كوحدة للمعالجة اذ ان الكلمة اذا كانت جديدة شكليا بزيادة حرف على سبيل المثال لن يعرفها النموذج، هذه الطريقة تم استخدامها في نموذج fasttext الخاص بشركة facebook، حيث انه استخدم بالاساس مجموعة حروف بدل من كلمات محددة و قد اظهر تحسن ملحوظ عن استخدام الكلمات فقط في معمارية CBOW و skip-gram لاستخراج المتجهات.

محاكاة البيانات التسلسلية (Sequential modeling)
تعد البيانات النصية بيانات تسلسلية، إذ ان ترتيب الكلمات قد يغير المعنى تماما و بالتالي لكي يستطيع نموذج تعلم ما يحتويه النص لابد ان يأخذ في الاعتبار التسلسل و ترتيب الكلمات، و هذا ما لم يفعله ايا من النماذج السابق ذكرها، كما ترى في المثال هنا ان استخدام الشبكة العصبية التقليدية (ANN) ليس لديه اي معلومة عن ترتيب النص لان تغير النص لن يغير في معادلته شئ.
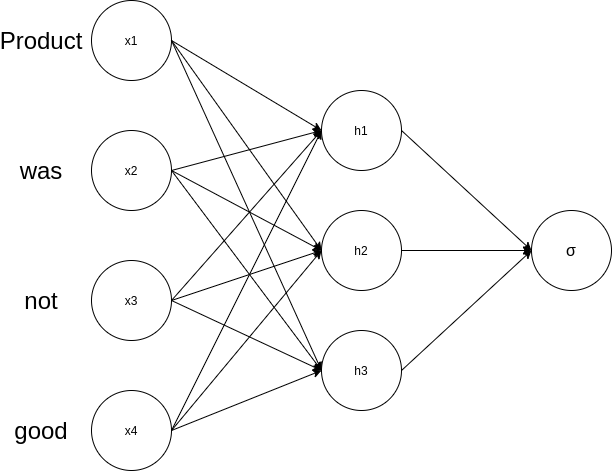
\(W_{1,1}*'product'+W_{1,2}*'was'+W_{1,3}*'not'+ W_{1,4}*'good'\)
لاحظ هنا ان اختلاف الترتيب لن يغير في المعني شئ لانه لا توجد آلية لتعلم العلاقة التي تنشئ من ترتيب الكلمات بشكل معين.
يمكننا تعديل هذه المعمارية بإضافة آلية لتعلم العلاقة التي تنشأ من ترتيب النص كما يلي
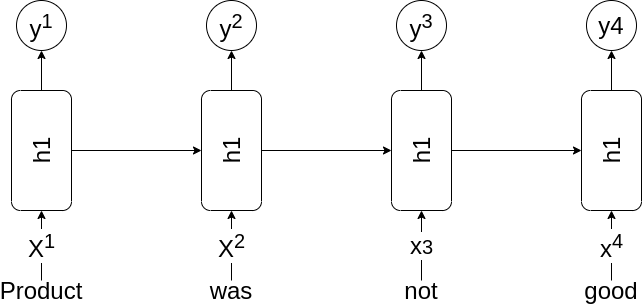
كما نرى هنا كل خطوة في هذه المعمارية تعتمد على الخطوة السابقة لها بالتالي يمكن للنموذج ان يتعلم ما يعنيه ترتيب الكلمات بشكل افضل.
الشبكة التكرارية تعمل عن طريق معالجة النصوص بالتتالي، اي ان نفس وحدة المعالجة (الخلية/cell) تقوم بمعالجة الكلمة الاولى ثم الكلمة الثانية و هكذا و لاحظ هنا ان نفس الوحدة تعالج الكلمات بالتتالي و هذا يمنحها القدرة على تعلم العلاقة الموجودة بين الكلمات بناءا على ترتيبهم.

المصدر
تقوم هذه المعمارية ببناء فكرة عن النص في كل خطوة زمنية، و هنا الخطوة الزمنية تعني ترتيب الكلمات اي ان الخطوة الزمنية الاولى هي الكلمة الاولى و هكذا، ويمكننا القول ان عند اي نقطة زمنية تقوم الشبكة بتكوين معلومات عن النص حتى هذه النقطة في الزمن و بالتالي عند اخر كلمة ستكون الشبكة كونت فكرة عن النص ككل.
يمكن استخدام هذه المعمارية في حل العديد من مسائل معالجة اللغة كما يلي.
الشكل السابق يمثل 5 انواع من مسائل معالجة اللغة
- الاول (one-to-one) يمثل الطريقة غير التسلسلية حيث حجم المدخلات و المخرجات ثابت.
- الثاني (one-to-many) عندما نستخدم مدخل واحد مقابل اكثر من نتيجة مثل وصف الصور حيث يكون المدخل هو الصورة و النتيجة هي النص الذي يصف الكلمة و بالطبع يمكن ان يكون اكثر من كلمة.
- الثالث (many-to-one) يعبر عن اكثر من مدخل (قطعة نصية على سبيل المثال) مقابل نتيجة واحدة (تصنيف النص اذا كان ايجابي او سلبي على سبيل المثال).
- الرابع (many-to-many) هنا يتم استهلاك المدخلات كلها قبل ان يتم بناء النتيجة والامثلة على هذا النوع تشمل (الترجمة الآلية و تلخيص النصوص و غيرها).
- الخامس (many-to-many) مثل السابق ولكن هنا يوجد نتيجة مباشرة لكل وحدة مدخلة (الوحدة قد تكون كلمة او حرف او مجموعة حروف (character n-grams) على حسب تعريف المدخلات) و احد الامثلة على هذا النوع هو التعرف على الاسماء المعرفة في النص (Named Entity Recognition).
كيفية عمل الشبكة التكرارية (RNN)
تعمل الشبكة التكرارية على تعلم العلاقة التي تنشأ من ترتيب النصوص عن طريق تعلم مجموعة من المتغيرات التي تحدد ما الذي يجب تعلمه من النص الحالي و ما الذي يجب تعلمه من الخطوة السابقة (t-1)، كما نرى في الرسم الآتي:
- ان الكلمة الحالية (Very) يتم معالجتها لتوليد متجه يعبر عنها (Very vector).
- يتم معالجة هذا المتجه من خلال المصفوفة X(t) و هي المسئولة عن اضافة ما يجب اضافته و ازالة ما لا تحتاجه الشبكة لتعلم ما يعنيه النص.
- الخطوة السابقة للشبكة (RNN Hidden state t-1) التي تمثل المعالجة الناتجة عن الكلمات السابقة يتم معالجتها من خلال مصفوفة اخرى a(t-1) حيث يكون هدفها تعلم ما يجب ان يتم اضافته من الخطوات السابقة و ما يجب ان يتم ازالته.
- يتم الجمع بين الخطوتين 2 و 3 و معالجتهم من خلال مرحلة غير خطية تمثلها هنا الدالة tanh و ينتج عنها متجه يعبر عن حالة/فهم الشبكة للنص حتى هذه اللحظة (RNN Hidden state t).
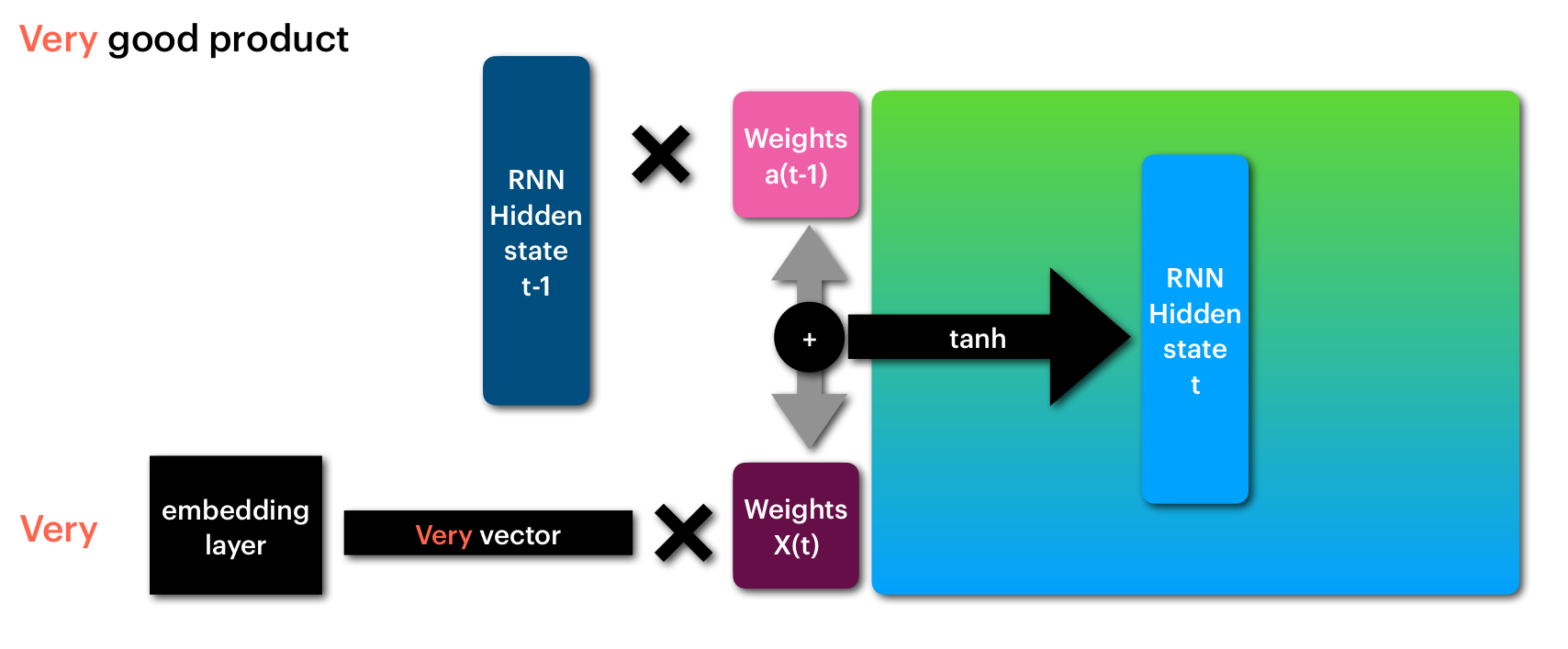
معالجة الكلمة الاولى من النص (Very)
ثم يتم تكرير الخطوات السابقة باستخدام نفس المصفوفات X(t) و a(t-1) مع الكلمة التالية كما هو موضح بالشكل الاتي
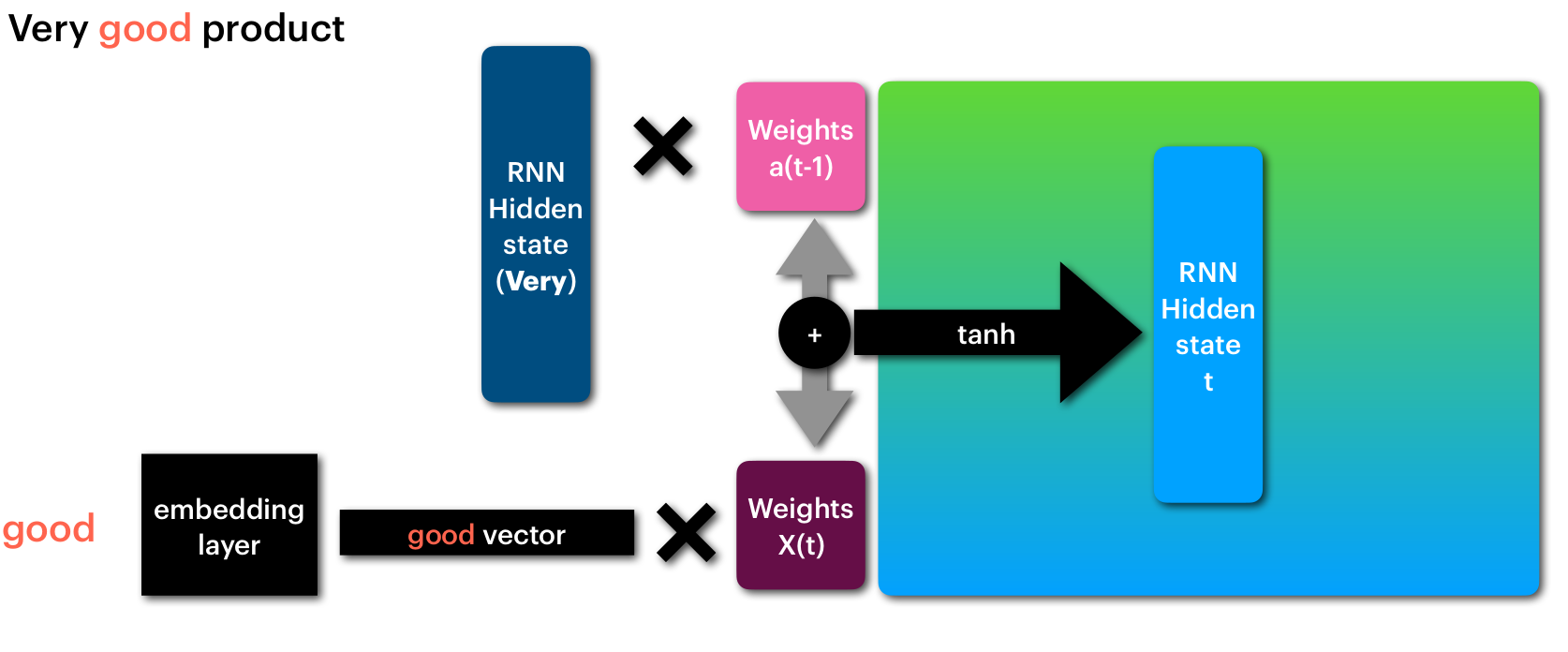
معالجة الكلمة الثانية من النص (good)
هذه العملية تسمح للشبكة بعد التدريب و تعديل قيم متغيراتها باستخدام النزول التدريجي و تصحيح اخطائها بان تتعلم القيم المناسبة للمصفوفات الخاصة بها لكي تستطيع تعلم النص بشكل يناسب المسئلة التي نقوم بحلها.
الشبكة التكرارية ذات الابواب (Gated Recurrent Unit)
الوصف السابق للشبكة التكرارية يعاني من مشكلة اساسية و هي ان مع طول النص سيكون من الصعب على الشبكة تذكر ما كان في بداية الجملة لان كما نرى في آلية العمل هنا ان الكلمة الحالية و الحالة السابقة لديهم قدرة كبيرة على تغيير حالة الشبكة ولا يوجد آلية للابقاء على المعلومات السابقة في النص.
لذا تم استحداث نموذج معدل من الشبكة التكرارية هو الشبكة التكرارية ذات الابواب (Gated Recurrent Unit GRU) و هي كما يقول الاسم عبارة عن شبكة تكرارية ولكن مع اضافة بوابات، تقوم هذه البوابات بالسماح للشبكة بالحفاظ على معلومات من خطوات سابقة عن طريق تعلم مجموعة متغيرات جديدة تكون البوابة التي تتحكم في مرور او عدم مرور المعلومات الناتجة من الكلمة الحالية و الكلمات السابقة كما هو موضح بالشكل الاتي.
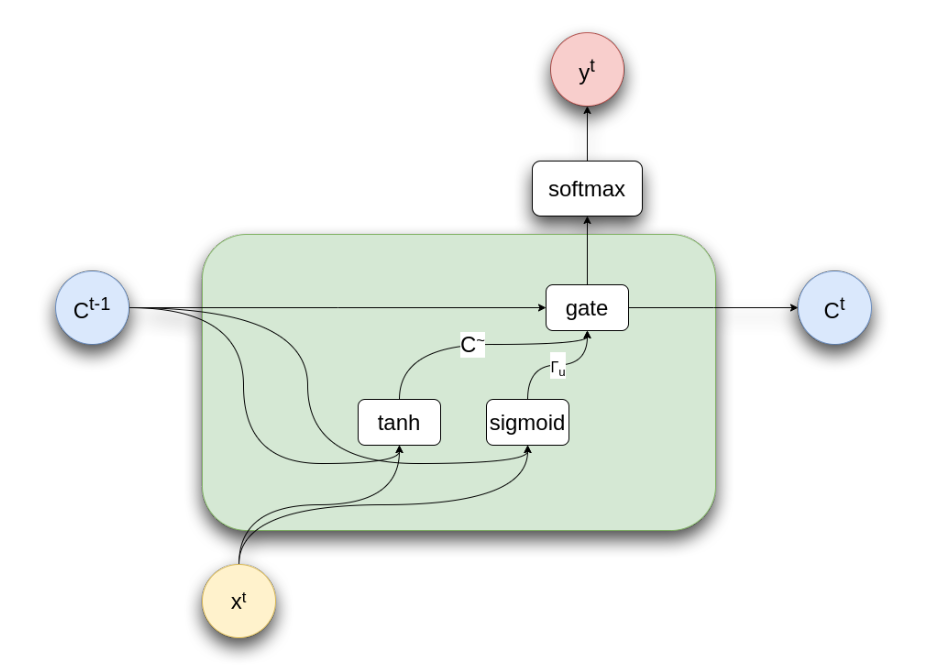
GRU
لفهم اعمق لما يحدث هنا دعنا نلقي نظرة على المعادلات لهذا المجسم
\[\tilde{C} = tanh(W_c [C^{t-1}, X^t] + b_c)\]
هذه المعادلة تمثل الشبكة التكرارية العادية (Vanilla RNN)
\[\Gamma_u = \sigma(W_u [C^{t-1}, X^t] + b_u)\]
هنا يتم تعلم البوابة التي تتحكم في مرور المعلومات من الكلمة الجديدة و الكلمات السابقة، و كما ترى هنا فهي معادلة تعتمد على الكلمة الحالية Xt و الحالة السابقة للشبكة C(t-1)

عند هذه النقطة لدينا المتجه Ct الذي يعبر عن الحالة الجديدة من الكلمة الحالية و كذلك المتجه r الذي سوق يستخدم كبوابة للتحكم في مرور المعلومات
لتكوين الحالة الجدية للشبكة Ctتقوم البوابة في التحكم في مرور المعلومات من الخطوة السابقة و الخطوة الحالية حيث كما نرى الجزء الاول r*C يتحكم في مرور المعلومات من الخطوة الحالية و الجزء الثاني (1-r)*C(t-1) يتحكم في مرور المعلومات من الخطوة السابقة.
لاحظ هنا ان البوابة r تنتج من دالة sigmoid اي ان قيمها ستكون من 0 ل 1 بالتالي يمكنك التفكير فيها على انها تمنع قيم و تمرر قيم كما ترى في الشكل التالي.
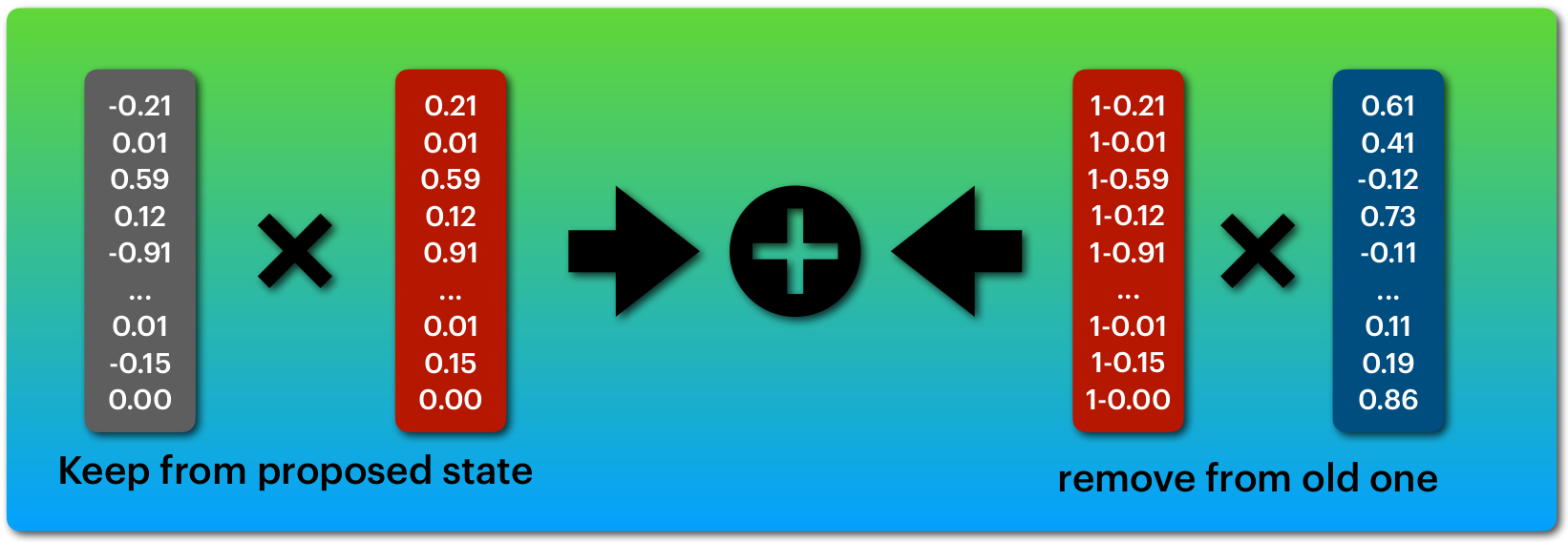
ما يتم ازالته من متجه يتم تعويضه من المتجه الاخر
تسمح هذه المعمارية بالاحتفاظ بمعلومات سابقة على عكس الشبكة التكرارية التقليدية، لهذا يمكنها معالجة نصوص اطول.
الشبكة ذات الذاكرة الطويلة و القصيرة المدى (Long Short Term Memory - LSTM)
استخدام البوابات في التحكم في مرور المعلومات يسمح للشبكة بتعلم النصوص الطويلة نسبيا و على غرار الشبكة ذات البوابات تم ايضا بناء نوع اخر من الشبكة التكرارية و هي الشبكة ذات الذاكرة الطويلة و القصيرة المدى (Long Short Term Memory - LSTM)، و تقوم هذا المعمارية بإضافة اكثر من بوابة للتحكم في مرور المعلومات و تعمل على اضافة ذاكرة طويلة المدى للحفاظ على المعلومات القديمة و كذلك ذاكرة قصيرة للتعبير عن المعلومات القريبة في النص.
المبدأ المستخدم في الشبكة ذات الذاكرة لايختلف كثيرا عن ذات البوابات، حيث يوجد في الشبكة ذات الذاكرة ثلاث بوابات.
- بوابة النسيان (Forget Gate) تتحكم فيما يتم ازالته او اضافته على الذاكرة الطويلة السابقة (اي الذاكرة الطويلة الناتجة من الخطوة الزمنية السابقة)
- بوابة التحديث (Update Gate) تتحكم فيما يتم ازالته او اضافته على الذاكرة الطويلة الجديدة (اي الذاكرة الطويلة التي سوف تنتجها الخطوة الزمنية الحالية)
- بوابة النتيجة (Output Gate) تتحكم في الذاكرة قصيرة المدى الناتجة من الخلية الحالية
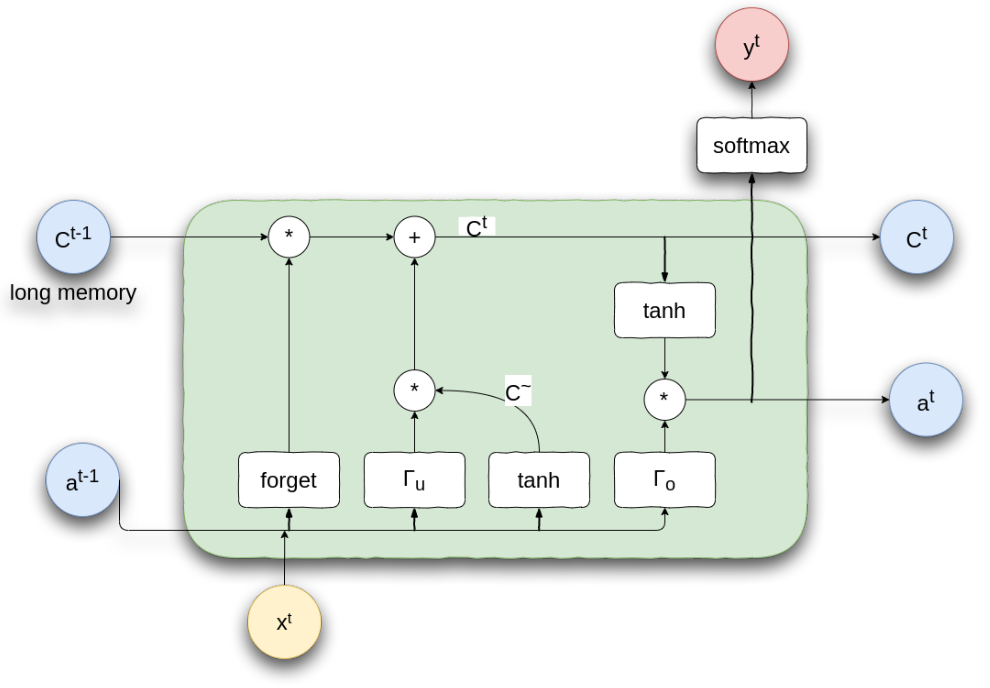
Long Short Term Memory
تعمل البوابات بشكل مشابه لما سبق شرحه، ها هي المعادلات لفهم افضل لما يحدث.
بوابة النسيان
\[\Gamma_f = \sigma(W_f [a^{t-1}, x^t] + b_f)\]بوابة التحديث
\[\Gamma_u = \sigma(W_u [a^{t-1}, x^t] + b_u)\]بوابة النتيجة
\[\Gamma_o = \sigma(W_o [a^{t-1}, x^t] + b_o)\]الذاكرة المقترحة C~
\[\tilde{C} = tanh(W_c [a^{t-1}, x^t] + b_c)\]الذاكرة طويلة المدى
\[C^t = \Gamma_u*\tilde{C} + \Gamma_f*C^{t-1}\]
لاحظ هنا ان الذاكرة الطويلة الجديدة يتم تكوينها عن طريق الذاكرة الطويلة للخطوة السابقة بعد تمريرها على بوابة النسيان اضافة الي الذاكرة الجديدة المقترحة بعد تمريرها على بوابة التحديث، وهذا يسمح للشبكة بالتحكم فيما يتم تمريره من الذاكرة السابقة و ما يتم تمريره من الذاكرة المقترحة.
الذاكرة قصيرة المدى
\[a^t = \Gamma_o*tanh(C^t)\]تعديلات الشبكة التكرارية
كأي شبكة عصبية يمكننا اضافة اكثر من طبقة من نفس النموذج لزيادة تعقيد النموذج و بالتالي تمكينه من تعلم انماط اكثر تعقيدا و لكن الشبكة التكرارية بطبيعة الحال تعاني من كونها تكرارية و يجب على كل الكلمات ان تمر بالشبكة كلمة تلو الاخرى مما يعني ان لمعالجة الكلمة الثانية في الطبقة الثانية من الشبكة يجب على كل الكلمات السابقة في نفس الطبقة ان تكون انتهت من المعالجة و كذلك كل الكلمات السابقة في الطبقات السابقة لها مما يجعل من الصعب تحقيق اقصى استفادة من الموارد المتاحة لتدريب نماذج اكبر.

يمكننا ايضا جعل الشبكة التكرارية ترى في الاتجاهيين، بمعنى ان في اي لحظة زمنية يمكن للشبكة معرفة الكلمات السابقة و الكلمات القادمة و هذا يمكن ان يكون مفيد للغاية في تطبيقات مثل التعرف على الاسماء المعرفة (NER) على سبيل المثال، و يسمى هذا النوع من الشبكة بالشبكة التكرارية ثنائية الاتجاه (Bi-Directional RNN).
لتحقيق هذا يمكننا استخدام شبكتين تكراريتين، واحدة تعالج النص من اليمين لليسار و الاخرى تقوم بالعكس، وعند معالجة الكلمة نستخدم مجموع ما تعلمته الشبكة و الاولى و الشبكة الثانية مما يضيف ثراء معلوماتي للكلمة.
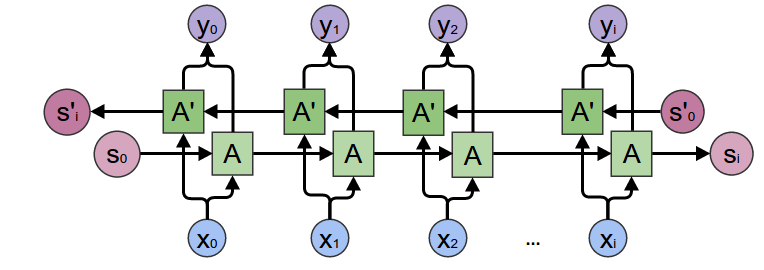
لاحظ هنا ان كل شبكة لاترى النص ككل و انما تراه جزء فقط، اي ان الشبكة التي تعمل من اليسار لاترى الا الكلمات السابقة لها ولا ترى الكلمات التي سوف تأتي لاحقأ وكذلك الشبكة التي تعمل من اليمين لاترى الا الكلمات يمينها ولا ترى الكلمات في اليسار، لذلك يعتبر استخدام النموذج ثنائي الاتجاه تحايل على رؤية النص كله ولكن فعليا هذا لايحدث هنا بشكل كامل.
حدود الشبكة التكرارية
بسبب طبيعتها التكرارية كما ذكرنا من قبل فان الشبكة التكرارية تعاني عدم القدرة على الاستغلال الأمثل للموارد بمعنى انه لا يمكننا تدريب طبقات هذه الشبكة بالتوازي لان الخطوات الزمنية تعتمد على بعضها البعض لذا يجب على كل خطوة انتظار الخطوة السابقة لها مما يمنع تدريبها بشكل متوازي.
ايضا الشبكة لا تر النص بشكل كامل كما ذكرنا حتى مع استخدام ثنائية الاتجاه لان كما ذكرنا كل شبكة ترى فقط الكلمات السابقة على حسب اتجاهها.
وعلى الرغم من استخدام البوابات و الذاكرة للاحتفاظ بالمعلومات الا انه من الصعب الاحتفاظ بكل المعلومات مع طول النص المعالج لذلك يتم فقد جزء من معلومات النص.
الاستنتاج
في هذا المقال تحدثنا عن مبدأ ال word embeddings او تمثيل النصوص باستخدام متجهات تعبر عن المعنى و التي كانت قفزة كبيرة في عالم معالجة اللغة و ايضا تكلمنا عن طريقة عملها و طرق مختلفة في تطبيقها.
تناولنا ايضا استخدام معماريات مختلفة مثل CNN و LSTM و كيفية عملهم و الصعوبات التي تواجه بعض النماذج.
في المقال القادم سوف نتعرض لمعماريات (architectures) جديدة استطاعت ان تتغلب على ما سبقها في عدة مهام مما جعلها احدث ما ورد في المجال (State of the Art) حتى تاريخ كتابة هذا المقال
في هذا المقال حاولت تبسيط بعض المصطلحات للغتنا العربية من اجل تسهيل عملية الشرح ولتبسيط المعلومة، في حالة اي خطأ املائي او اقتراح افضل للترجمة فأنا ارحب جدا بذلك يمكنك التعليق على المقال او مراسلتي لتعديل و تحسين المحتوى، ووفقنا الله وإياكم لما يحب ويرضى.




Comments